モダンを極める: 2022年、IBM i HA/DR計画を策定すべき時
災害や、計画外のダウンタイムというものには、アプリケーションやデータがどこに置かれているかにかかわらず、いつでも、どの企業でも襲われる可能性があります。ハイ アベイラビリティ(高可用性)およびディザスター リカバリー(災害復旧)(HA/DR)計画を策定することは、ミッション クリティカルなIBM iアプリケーションおよびビジネスを、迅速に稼働可能な状態に復旧する前提となるものです。
2021年も、相応の試練に見舞われました。森林火災から、地震、洪水、そしてパンデミックの継続まで、あらゆることが起こりました。これらはいずれも母なる自然がもたらした試練です。一方、サイバー攻撃やランサムウェアといった、人間が作り出したリスクについても忘れてはなりません。それらは2021年には指数関数的に増加しています。 毎日30,000件以上のセキュリティ侵害が発生しているため、組織は自らを防御し、あらゆる事態から復旧することができるよう、準備を整えておく必要があります。
そこで、次の重要な問いを、自分自身に問い掛けてみてください。
- インシデントが発生した場合に、どれくらい迅速に復旧できるか。
- 災害がビジネスにどのような影響を及ぼすか。
- 災害に襲われた場合に、すべてのシステムおよびデータの復元についてどの程度自信があるか。
これはいつも言っている冗談なのですが、計画というのは、バックアップアイテムを車のトランクに放り込んでおくこととはわけが違います。計画を策定していても、策定してあるだけは確実に復旧するのには十分とは言えません。これまでに実際にテストを実施して、復旧できることを実証済みでしょうか。その計画によって潜在的なダウンタイムが最小化されるでしょうか。また、その計画は復旧コストに対して最適化されているでしょうか。復旧計画は誰にでも必要であるため、自分にとって適切な計画というのは、どのように策定したらよいのでしょうか。
検討が必要になる重要な点はいくつかありますが、大きなものとしては、リスク許容度、復旧要件、そして様々な戦略のうち自分にとって最適なのはどれなのか理解しておくこと、があります。
リスク許容度は、目標復旧時点(RPO: recovery point objective)と、目標復旧時間(RTO: recovery time objective)について理解することによって明らかになります。目標復旧時点(RPO)は、その企業がどれくらい多くのデータを消失のリスクに晒す用意があるかを表すものであり、目標復旧時間(RTO)は、その企業がどれくらい長いダウンタイムを許容する用意があるかを表すものです。これら2つの要素の両方が、HA/DR戦略の選択肢とコストを決める要因となります。
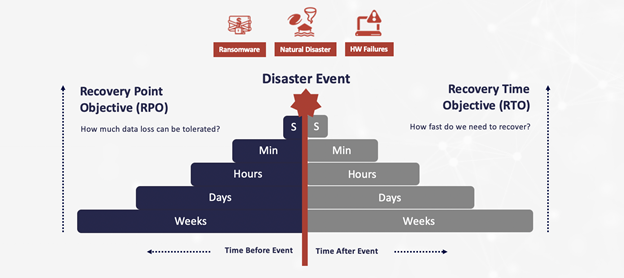
様々な戦略を見比べてみることが大事ですが、その際、頭の片隅に置いておくとよいのは、目標復旧時点は、小刻みに設定すればするほど、コストは多く掛かるということです。秒単位での設定は分単位より費用が掛かり、分単位は時間単位より費用が掛かります(以下同様)。そのため、まずは、ダウンタイムの実際のコストおよび影響が企業にとってどのようなものであるか理解しておくこと、どのアプリケーション、データ、システムがクリティカルなものであるか理解しておくこと、そして目標復旧時間はどれくらい必要かについて合意を取っておくことが極めて重要です。
検討してみるべきいくつかの重要な点を以下に示します。
- どのアプリケーションおよびデータが企業にとってクリティカルなのか。
- 誰が、どのように、それらを使用しているのか。
- それらのアプリケーションおよびデータはどこに置かれているのか。
- それらはどのようにして管理され、アクセスされ、セキュリティが確保されているか。
- それらはどのようにバックアップされているのか、それらをリカバリーするにはどのようなことが必要となるか。
- それらがどれくらいの時間ダウンすることを許容できるのか。
HAとDRの違いを理解する
ディザスター リカバリー(DR)をベースラインとして、ハイ アベイラビリティ(HA)をゴールド スタンダードとして考える人は多いようです。しかし、実際には、ディザスター リカバリーは、むしろ「あるメディアから別のメディアへシステム全体を復元する」シナリオと考えるべきです。
ハイ アベイラビリティは、システムを利用可能にしておくためのものですが、必ずしも別個のデータセンターまたは別個のサイトで利用できるようにすることを意味するわけではありません。実際のところは、多くの企業にとってハイ アベイラビリティとは、たとえクラッシュか何かがあった場合でも、確実にマシンが動作できるようにするための、あるいはライブ システムのパッチングを可能にするためのローカル レプリケーションのことであり、一方、ディザスター リカバリーは、プライマリー サイトが自然災害(ハリケーンや洪水や火災)または非自然災害(ランサムウェア攻撃など)によって壊滅状態になった場合に、リモート サイトでワークロードを稼働させる方法のことです。
同一のデータセンター内で2台のマシンを並べていて、メンテナンスを行い、両者間でデータを行き来させることができる場合、それはハイ アベイラビリティ ソリューションと呼んでもよいかもしれません。その場合でも、ディザスター リカバリー ソリューションを構築しておく必要はあります。この例で言えば、2台のサーバーが置かれている建物が暴風雨に襲われたり、メインの回線がダウンして接続が失われたりした場合に、それでもアクセスを復元する方法が必要です。
しかし、HAおよびDRを定義する場合、大事なのは、誰にとっても両方の計画が必要だということです。両方の計画を策定していないことの言い訳は、2022年には通用しません。当然なことながら、どのIBM iのショップも、ますます敵意が高まりつつある世界で、保護が必要な、ミッション クリティカルでビジネス クリティカルなアプリケーションを稼働しているからです。
テープベースのソリューション
テープ バックアップは、ディザスター リカバリー計画としては、最小限の手段です。公正を期すために言えば、テープ ソリューションにも、中には高機能なものもあるようです。ただし、ほとんどの実装はそうではありません。多くの企業では、日単位ではなく週単位で、テープ ドライブでテープをローテーションさせています。そしてテープ ライブラリーがある場合は、7本すべてのテープを差し込んで、次の週に7本すべてのテープを取り出します。それらのテープはテープ ライブラリー内にあり、オフサイトでない場合は、必ずしも保護されるとはかぎりません。
テープベースのソリューションにおける目標復旧時点は、実のところは、実行しているバックアップの頻度と種類によって決まります。毎日、フル バックアップを取っている場合、RPOは24時間以下ということになります。最後のバックアップが取られた時点は常に、そこへ戻る必要がある時点になり、言い換えれば、その時点のデータには戻ることができるという時点です。また、週1回、フル セーブが行われているという場合は、RPOは7日となります。RPOが7日というのは、実際、その企業は、7日分ものデータの消失(それに加えてシステム再構築の時間)を許容できると決めていることを意味します。
以下は、やってはいけないことを教えてくれる、ちょうど良い顧客事例です 。週次バックアップ戦略を採用していたあるクライアントが災害に見舞われました。リカバリーを実施しようとしたところ、数多くのテープがあることには気付いたものの、中にどのようなデータが入っているかよく分からないということで、支援を求められたケースでした。
バックアップ マシンと200本のバックアップ テープが持ち込まれましたが、それらのテープに何が収められているのかは分からなかったため、担当チームが調査して、すべてのテープの内容のカタログを作成することになりました。それらに目を通して分かったのは、実は、バックアップは8か月間実行されていなかったということでした。ここで1つ、リソースに関する問題発生です。クライアントにはIBM iリソースがなかったため、バックアップは実行されなかったということです。誰にとっても幸いなことに、結末はハッピー エンドでした。ハード ドライブからデータを取り出して、マシンを復旧して稼働することができたのです。しかし、SoR(記録のためのシステム)が15日間ダウンしていたわけなので、15日分のデータは失われたことになります。テスト済みのDR計画はありませんでした。DR計画の検証もなされていなかったということです。
この一件を通じて改めて思ったのは、ランサムウェアの話になった場合、テープというのは、アクセスできない方法でデータを保護するという、セキュリティ当局によるエア ギャップの要件を実際に満たす数少ないソリューションの1つだということでした。
仮想テープ ライブラリー(VTL)
VTLは、基本的には、テープ ライブラリーをエミュレートするアプライアンスがある、Disk-to-Diskバックアップです。たとえ、背後にあるのがはるかに高速なディスク アレイだとしても、IBM iはそのVTLを、テープが中にあるテープ ライブラリーと見なします。
VTLについては気に入っているところが2つあります。もっとも、どちらをより気に入っているのかと問われると、何とも言えません。1つは、そのスペース内にすべてが収められているため、実際にテープを操作する必要がないところです。もうひとつは、レプリケーション機能です。つまり、VTLはオフサイトの別のアプライアンスに自動的にデータを複製できるところです。使用される帯域幅はかなり少なくて済みます。複製はバックアップが行われるとほぼ同時に行われます。アプライアンス構成が適正に行われている場合、そうしたデータはオフサイトに複製されます。したがって、毎日、バックアップとともにデータがオフサイトに送られることになります。
これを、ディザスター リカバリー契約、またはリカバリー先として指定できる別のマシンと組み合わせることで、DR計画としてかなり信頼性の高いものになります。
これらはすべて、 Abacus 社および Fresche 社が顧客向けに提供しているサービスです。Abacus社およびFresche社では、HA/DR計画策定の支援、このようなBTLを使用したリモートでのバックアップの管理の支援、Abacus/Frescheサイドへのバックアップの複製、リカバリー用のインフラストラクチャーの提供、年次DRテストの実施代行など、様々な支援サービスを提供しています。すぐに使えるものばかりです。
ハイ アベイラビリティ
ここでようやく、RPO/RTOの数値が動き始めます。HA向けのソフトウェア ベースの選択肢には、MIMIX、iTera、Maxava、QuickEDDのようなソリューションがありますが、Abacus社と同様に、ほとんどの企業が、それらすべてをサポートしているため、顧客にとって適切なソリューションを自由に選ぶことができます。
ソフトウェアベースのレプリケーションにまつわる1つの大きな問題は、高価だということです。もっとも、以前と比べれば、ずいぶん安価になっているのは確かであり、セカンダリー マシンのコストも大幅に下がっています。また、ほとんどのソリューションでは、システムで多くのオーバーヘッドも発生します。管理に関して豊富な専門知識が求められるため、それに付随して高い人件費が必要となります。また、ライセンス費用も必要であり、さらには、サイトに2台のマシンが必要となります。
ジャーナル管理が必要になるため、より多くのディスク スペース、より多くのプロセッサー、ライセンシングのようなもの、およびマシン間のネットワークを使用するようになります。私のお気に入りのソリューションではありませんが、間違いなく機能し、市場でもそれなりの存在感があります。使う人が使えば、良いソリューションとなるでしょう。通常は、本番システムをより稼働させるように、バックアップをターゲット システムから取ることもできますが、その場合、すべてを複製するわけではありません。オペレーティング システムの一部や他の複製されないもののように、複製する対象の調整および管理が必要になります。そして、目標復旧時点は、2台のマシン間の帯域幅と本番マシンの負荷によって決まります。本番マシンの負荷が高い場合、ジャーナルはバッファリングされ、データが直ちに回線を通じてセカンダリー マシンに送られることはありません。日中に、何時間もの遅延が生じているマシンがありますが、それらは、負荷の少ない夜間に、遅れを取り戻します。そして、夜間に負荷が高い場合は、おそらく、日中に遅れを取り戻します。けれども、実際には、マーケティングで言われているような、「1時間未満」ということはありません。
といったところから、私のお気に入りのHAソリューションの1つは、ストレージ エリア ネットワークでのハードウェア ベースのレプリケーションということになります。このレプリケーションは、ストレージ レイヤーで行われます。したがって、システム(オペレーティング システム、PTF、マシンの一部であるすべてのデータのブロック)内にあるすべてのデータが、見えないところでSANによって複製されます。IBM iプラットフォームは、複製が行われていることを知りません。
データは、ローカルSANに複製することも、バックアップ サーバーに接続されたリモートSANに送り出すこともできます。バックアップ サーバーは、必要ならワークロードを稼働することもでき、また、プライマリー データセンターで本番マシンのパフォーマンスに影響を与えることなく、フル バックアップを他のメディアに送り出すこともできます。これを可能にするために、大幅な圧縮が行われます。ハードウェア レプリケーションが人気を集めているのは、ストレージ コストが下がり、アルゴリズムの改善によってさらなる圧縮が実現可能になっているためです。たとえば、データを複製するのに10Gb/秒のサーキットは必要なくなったとします。そうであれば、大幅な節約になります。目標復旧時点は、構成に従って、同期ミラーリング程度までに短くすることができるようになります。これは、本番ストレージに書き込まれたすべてのデータのブロックが、ターゲット ストレージに書き込まれることを意味します。ほとんどの顧客が、15分未満の復旧時点でより多くのデータの復旧を目指しています。これは、複製されたSANをホスティングしている2つのデータセンター間の距離次第では、パフォーマンス ヒットが生じる可能性があるからです。
重要なことに、SANでは他にもこのようなオプションを選ぶこともできます。すなわち、ストレージをエア ギャップすることです。万一、ランサムウェア イベントが発生した場合の備えとして、顧客がロールバック ポイントを利用できるように、毎日、毎時間ごとに(本番マシンでスナップショットの数を選びます)スナップショットを取ることができます。
たとえば、本番マシンで日次スナップショットを取っていて、月曜日の朝に出社して不正侵入に気付いたとします。この場合、直前の6日分のマシンのイメージがあるため、それらのいずれか1つをオンにしてから、以前に作成したバックアップを使用して、リスクに晒してしまったかもしれないデータを抽出することができます。目標復旧時点および目標復旧時間の関連では、実に素晴らしいオプションがあります。Db2 Mirrorのようなデータ レプリケーションや、あるいは、ジャーナリングまたはiASP関連で行なえることもあります。
1つ奇妙な問題があるのですが、お気付きでしょうか。レプリケーションが高速であればあるほど、ランサムウェアに対してより有効になります。したがって、早めのエア ギャップ、頻繁なエア ギャップが必要です。確実にクリーン コピーへ戻すことができるようにするためには、長期間、多くのポイント イン タイム レプリカを保持する必要があります。リストア元となるクリーンなデータおよびアプリケーションのセットがあることを確認する方法が、何かしら必要です。そのお手伝いは、私たちにお任せください。
IBM iのショップには、このことを真剣に受け止めていただきたいと思います。 今すぐにです。ランサムウェアは、2022年に発生しそうな災害のうち、一番、遭遇しそうな災害だからです。私たちは、30年間にわたってディザスター リカバリーおよびハイ アベイラビリティを実施してきました。これまでに処理した実際の災害(テストではなく、顧客が建物の壊滅等の被害にあった実際の災害)の件数は、20数件ほどになります。2021年には、ランサムウェア関連のリカバリー案件で、すでに顧客30社の支援を行っています。これが実情なのです。
Abacus社には、HAおよびDRシステムをセットアップするノウハウが豊富にあります。また、その運用の支援に利用できるマネージド サービスも提供しています。さらに、HA/DRセットアップの一部としてIBM iをクラウドにホスティングすることも可能です。Fresche社サイドでは、もちろんアプリケーションについてお手伝いいたします。お問い合わせをいただけましたら、2022年に向けてのより良いHA/DR戦略を構築するために、どのようなお手伝いかできるかについて、喜んでご説明させていただきます。詳細については、 info@freschesolutions.comまでお問い合わせください。









