Power Systems、帯域幅の増加で高速化の道は開ける
IBM i の顧客の大半がPower Systemsハードウェアに求めるもの(特に演算能力に関して)と、IBMが提供できるものとの間のギャップは、2010年のPower7世代以降、拡大してきました。しかし、チップ製造プロセスにおけるムーアの法則の進化スピードがスローダウンしたおかげで、そのギャップは縮まり始めています。IBMがそうなることを求めたからではなく、物理的な限界のためです。
そして、IBM i プラットフォームが主にトランザクションプロセッシングおよびアナリティクスを処理するデータベースプラットフォームであるとすれば、IBMが演算能力から軸足を移して、GPU、FPGA、および不揮発性メモリーを使用して、ありとあらゆるアクセラレーションを生みだすメモリーおよびI/Oの機能強化に向かうことは良いことです。理論上はですが。ただし実際のところは、ここ何年かの間にそのようなアクセラレーションが行われ、それが(Power Systemsではなく)Cognitive Systemsプラットフォームの重要な戦略的な側面になっているのだとしても、IBMでは、IBM i ワークロード向けにはGPUおよびFPGAアクセラレーションを十分には活用しきれていないようです。フラッシュメモリーを使用したストレージの高速化の促進という点では、IBMはかなり良い仕事をしてきましたし、また同社は、エントリーPower9システムにおいて自社製の「Centaur」バッファードDRAMの採用を止め、標準的なDRAMへ移行したことにより、エントリーPower9システムのメイン メモリーのコストダウンをもたらしました。大容量で安価なメインメモリーとフラッシュストレージと十分な演算能力とを組み合わせれば、2ソケット サーバー フォーム ファクターの領域ではほとんどのIBM i のショップの現在のニーズは満たされることでしょう。
しかし、将来を見据えて、IBM i のショップで稼働できる、そして稼働するべきより広範囲に渡るワークロードに目を向けてみましょう。IBMは、苦労を惜しむことなくDb2 for IBM i データベースをリブランドして(実際には、それをモダナイズするようなことは一切行いません)、すごい勢いでそれを高速化しているため、Db2 for IBM i はより多くの作業をより高速に行うことができるようになるだけでなく、先進的なアナリティクスおよび機械学習など、様々な種類の作業を行うこともできるようになります。以前に、アクセラレーションについて、そして我々がCognitive Systems/500と呼んできたシステムをどのようにしたらIBMが作り出すことできるかについて記事で取り上げてきたのは、このようなことが念頭にあってのことでした。私が提案したCognitive Systems/500は、AIおよびHPCワークロード向けのIBMのフラッグシップシステムとして昨年12月に発表されたPower9ベースのAC922システムに非常によく似たシステム(実在しないマシン)でした(Power9アーキテクチャーに関して最初に記した記事はこちらでお読みいただけます。今回の記事の理解に大いに参考になると思われます)。
IBMは先週、ラスベガスで「Think 2018」ビジネス パートナーおよび顧客カンファレンスを主催しましたが、同時期には、同社のパートナー企業が集まるOpenPower Summitも開催されていました。さらには、FacebookがOpen Compute Summitを開催していたのも同時期であったため、先週はインフラストラクチャーで大忙しの週となりました。ご想像のとおり、先週、IBMはピカピカの新たなPower9システムとSystem z14メインフレームについて多くのことを語りました。また、小誌でもこの数週間でPower9「ZZ」エントリー システムについて実に多くのことを語ってきました。率直に言って、Think 2018で語られたことよりも多いと思います。これはつまり、我々がきちんと自らの仕事をしているということになるのでしょう。しかし、OpenPower Summitで明らかにされた新しいことは、アップデートされたPowerプロセッサー ロードマップでした。これについては、OpenPower Foundationの初代プレジデントであり、IBMフェローで、IBMのCognitive Systems開発のバイスプレジデントのBrad McCredie氏が少し触れています。
新しいロードマップをじっくりご覧ください。
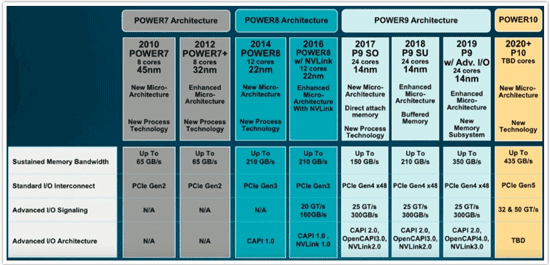
演算能力に注力することからI/Oに注力することへの変化は、Power8+チップから始まりました。このPower8+という名称の使用をIBMが止めたのは、このチップでも多少のマイクロアーキテクチャの改良があったものの、重要な変更点はCPUコアまたはキャッシュに関するものではなく、Nvidia社の「Pascal」P100 Tesla GPUアクセラレーターどうし、そしてIBMのPower8+プロセッサーと緊密に連結することを可能にするNVLink 1.0インターコネクトの統合だったということを強調したかったからでした。このチップは実際のところ、昨年末に発表された、小誌でも大きな期待を胸に長い期間に渡って取り上げてきたPower9チップのためのPOC(概念実証)でした。
お分かりのように、IBMはPowerチップ ファミリーのアップデートにおいて独自のtick-tockアプローチを取ってきましたが、これはIntelほど、タイトなスケジュールでもなければ、まったく同じ方式でというわけでもありませんでした。Intelのtick-tock方式では、tickは、たとえば、45ナノメートル チップ エッチング技術から32ナノメートル方式へのシュリンクなど、製造プロセスの変更であり、これに対して、tockは、コア設計、キャッシュ階層の変更、およびアクセラレーターの追加など、アーキテクチャーの変更です。リスクを軽減するために、Intelはプロセスの変更とアーキテクチャーの変更を同時に行わないようにしました。あまりにも多くのことが、間違った方に進むこともあり得るからです。近頃では、製造プロセスにおけるムーアの法則の進化は到達しづらくなっているため、Intelは、我々がtick-tock-clockと呼んでいる3ステップのプロセスに移行しています。3番目のステップではプロセスがさらに洗練され、パフォーマンスの改善は次の世代に先送りされることなく第3世代で現われます。14ナノメートルの後、トランジスタの物理的な限界に到達する前に、あまり多くのステップは残っていません。10ナノメートルから始まるとすると、次はおそらく7ナノメートル、次いで5ナノメートル、そしておそらく3ナノメートルくらいまででしょう。1ナノメートル程度の誤差はあるかもしれません。最初が10ナノメートルを切ってくるとしたら、7ナノメートル、次いで4ナノメートルでお終いかもしれません。その後は、個々の原子でのエッチングしか残されておらず、物理学または経済学的な観点から見て、実用化は難しいものがありそうです。
2010年のPower7チップでIBMは、45ナノメートルで8コアの実装を行い、次いで2年後のPower7+チップでマイクロアーキテクチャの微調整を行うとともに、一段と小さい32ナノメートル プロセスに移行しましたが、そのシュリンクを利用して製造コストを低減し、コア数は増やしませんでした。2014年のPower8では、22ナノメートルへのプロセス シュリンクを行っただけでなく、Powerコアの根本的な作り直しも行うとともに、コア数を50%増やしてチップ当たり12コアとしました。Power8には6コアのバージョンもあり、それら2つを1つにパッケージして12コアのソケットが作り出されました。その一方で、はるかに高価な、12コアすべてが1つのダイに収められたバージョンのPower8チップも提供されました。Power8チップはDDR3またはDDR4メモリーを使用でき、ダイに8つのメモリーコントローラーを搭載し、メモリー帯域幅はPower7およびPower7+チップに対して3.2倍増を実現しました。また、この2014年のPower8チップでは、PCI Express 3.0ペリフェラルスロットを使用し、Powerメモリー コンプレックスとアクセラレーターとのコヒーレントな接続のための最初のCAPI 1.0プロトコルがPCI Expressポート上で稼働できるようになりました。2年後のPower8+チップでは、プロトタイプの「Bluelink」汎用高速I/Oポートでの20Gb/秒の伝送が加わりました。これらの新たなI/Oレーンは、双方向で20Gb/秒の帯域幅の4つのポートを形成するのに使用され、NVLink 1.0ポートが構成されます。NVLink 1.0ポートではCPUとGPUの間の基本的なキャッシュ コヒーレンシが維持されたまま、4つのPascal P100アクセラレーターをPower8+ CPUに繋ぐことができます。
IBMがすでに発表したAC922およびZZシステムで出荷されているPower9「Nimbus」および「LaGrange」スケール アウトPower9チップでは、いくつか変わったことが起こりました。IBMは、パートナーであるGlobalFoundries社(4年前にIBM Microelectronics部門を買収)の14ナノメートル プロセスへ移行しました。このプロセス シュリンクにより、IBMは、1つのダイに、SMT4スレッディング(コア当たり4スレッド)の最大24のスキニー コア、または、SMT8スレッディング(コア当たり8スレッド)の12のファット コアを詰め込むことが可能になりました。基本的に、IBMでは、顧客の要望に合わせて、コア数を半分にしたり、スレッディング レベルを半分にしたりする変更を可能にしています。しかし、実際には、厳密な意味ではコア数が増えたわけではありません(SMT8の12コアはPower8およびPower8+でのサポートであり、これはPower9でのサポートでも同じです)。
エントリーPower9マシンでは、IBMはメモリー コストを下げたかったこともあったためか、自社製のCentaurバッファード メモリーおよびL4キャッシュから、ごく一般的なDDR4メインメモリーへと移行しました。Power9 SOダイにもやはり8つのメモリー コントローラーがありますが、バッファなしのため、持続メモリー帯域幅は、Power8およびPower8+のソケット当たり210GB/秒に対し、Power9 SOバリアントでは150GB/秒と、29%のダウンとなります。また、Power9 SOチップでIBMは、Bluelinkレーンの速度を25Gb/秒へ上げています。これは現行のイーサネットスイッチチップの最高速度と同等であり、Power9 SOプロセッサー上の6つのNVLinkポートを介して300GB/秒の帯域幅を提供できることを意味します。PCI Express 4.0ペリフェラルI/Oの48レーンへの移行により、他のペリフェラルのための帯域幅が2倍になります。OpenCAPI 3.0プロトコルはBluelinkレーンで稼働します(それらはNVLink 2.0のみのサポートでなければならないわけではありません)。また、アップデートされたCAPI 2.0プロトコルはPCI Express 4.0上で稼働できます。
単一システムイメージで4、8、12、または16ソケットの、Power Systemsの今後のスケールアップ バリアントで使用される「Cumulus」Power9チップでは、IBMは引き続きCentaur DDR4バッファードメモリーを採用するため、持続メモリー帯域幅はソケット当たり210GB/秒で変わりありません。チャートからは、SMT4スレッディングの24のスキニーコアを利用できるバリアントが存在することが見て取れますが、我々が知る限り、IBMでは、これらのマシンでSMT8スレッディングの12のファットコアを提供することを予定しているだけのようです。また、Bluelinkポートの帯域幅が同じままであることもチャートから見て取れますが、それらのBluelinkポートの一部は、ソケット間でNUMA共有メモリーを構成するのに使用されることになります。この点に関しては、第3四半期に登場予定の「Fleetwood」16ソケットPower E980システムについて分析した記事で指摘しています。その場合でも、いくつかのBluelinkポートが残されているためOpenCAPIを稼働することは可能であり、あるいはGPU、FPGA、またはフラッシュ アクセラレーターに繋ぐためにこれを行いたい場合はNVLinkポートが利用できます。
こうしたことから、2019年に登場予定の後続チップPower9+がもたらされます。Power9+はPower9バリアントとコア数が同じで、GlobalFoundries社の改良された14ナノメートル プロセスで実装される予定です。これらのPower9+チップでは何らかのマイクロアーキテクチャの改良が行われるでしょうが、少なくとも、コアとなるコンピュートコンプレックス部においては、パフォーマンス面で大きな変化はなさそうに思われます。けれども、メモリーサブシステムにおいて、そしてI/Oサブシステムで稼働するプロトコルにおいては機能強化がなされるでしょう。それらのコアへのデータ供給が改善されるため、今ある演算能力でより多くの処理を行うことができるようになります。これもまた、一種のパフォーマンスの向上です。
PCI Express 4.0およびBluelink I/Oサブシステムについては、信号速度およびピーク時および持続帯域幅の点で、このような将来のPower9+チップ ファミリーでは同じままでしょう。しかし、CAPI、OpenCAPI、およびNVLinkプロトコルはすべてアップデートされて改良されます。また、IBMは新たなメモリーサブシステムへの移行を行っていますが、それがどのように行われるのかについて、McCredie氏は次のスライドでいくつかヒントを示してくれました。
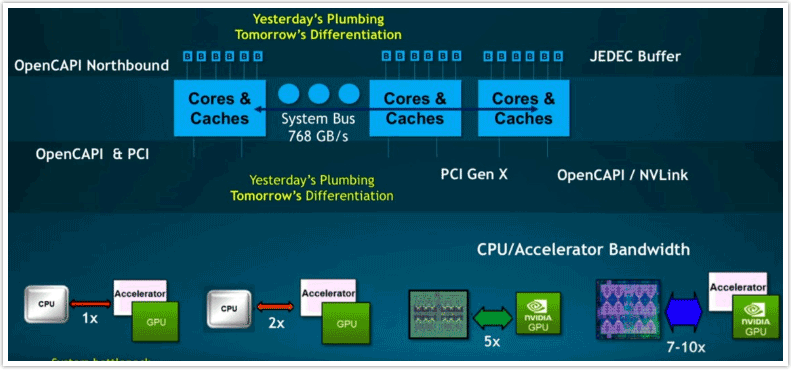
この図を文字通りに受け取れば、BluelinkポートはPowerコンピュートコンプレックスから出ている下側のI/Oに示されており、OpenCAPIおよびNVLinkポートを構成しています。しかし、上方向へ向かうBluelinkポートも示されており、これらはJEDEC準拠メモリー バッファに繋がっています。これはDDR4またはDDR5 DRAMメモリー用であろうと思われますが、DRAM同様にビットアドレス指定可能な、ReRAMまたは3D XPointのような、永続的な不揮発性ストレージ用でもあるかもしれません。
我々がIBMだったとしたら、これらのPower9+チップでは、コンピュートコンプレックスとDRAMの間にメモリーバッファを置いて、Bluelink接続のDDR4 DRAMのプレビューを行うかもしれません。Power9+チップでメモリー帯域幅67%増が実現されるとしたら、メモリーコントローラーの数を50%増やしてダイ当たり12にし、メモリースロットの数も50%増でバッファ付きでソケット当たり48スティックまたはバッファなしで24スティックに増やすことで可能となるかもしれません。Power9 ZZマシンの場合のようにすべてのスロットが使用されているときに、現行の3.2GHzから3.8GHzにメモリー スピードを上げた場合、その帯域幅を得ることができます。もちろん、これは推論に過ぎません。DDR5の規格策定は今年完成予定ですが、ことによるとIBMは、早めにギア ダウンしたDDR5メモリー スティックでこのようなことを行うかもしれません。DDR5メモリーは、実装された際には、DDR4の2倍の容量および2倍の帯域幅を提供することになります。
IBMは、当座しのぎのために、Power9+チップでメモリー スロットを増やしてくるだろうと我々は思っています。なぜなら、Power10チップが2020年か2021年に登場するまで、IBMはDDR5を待たなければならないからです。さらに言えば、今回のPowerロードマップでは両面作戦をとっているようです。しかし、Power10は、50Gb/秒のBluelinkシグナリングによって支えられた、一段とフレキシブルなメモリーサブシステムを持つような設計となると考えられます。また、システムの他の面では32Gb/秒のBluelinkシグナリングもサポートするでしょう(チャートではそれら2つの速度が利用可能であることが示されています)。Power10でDDR5に移行することにより、メモリー スロットの数をバッファ付きで32、バッファなしで16へ戻しても、メモリー スピードを3.4GHzに上げれば、チャートに示されている435GB/秒のメイン メモリーの帯域幅に到達することが可能となるでしょう。
また、Power10チップはPCI Express 5.0ペリフェラルもサポートすることになるでしょう。こちらも、PCI Express 4.0と比べてやはりI/O帯域幅が倍になります。Power10チップのコア数は未定ですが、これは、世界の主要なHPCおよびAIセンターでも、今から3年後にどのようなものが必要となるのか分からないためです。IBMが、たとえば、SMT4の36のスキニーコアまたはSMT8の18のファットコアなど、50%以上のコア数の増加を行うことはおそらくないだろうと思います。また、その一方で、予想されているように、GlobalFoundries社からの7ナノメートル プロセスでチップが実装されるのであれば、コア数を同じままにしておくだろうとも思われません。ところで、GlobalFoundries社自身は、ニューヨーク州マルタの工場での7ナノメートル製造技術については言葉を濁しています。同社には、7ナノメートルの従来型の液浸リソグラフィー技術もあり、加えて、最初のEUV(極端紫外線)リソグラフィーを7ナノメートルで行っています。したがって、IBMには、2つの方法があるということになります。一方はリスクが小さいと考えられますが、他方は製造ステップと複雑性がはるかに少なく、そのためコストが少なく済ます。
今なすべきは、IBM i ソフトウェアスタックや、IBM i と組み合わせて稼働できる各種Linuxアプリケーションを実際にIBMに再設計させ、これらの機能をフル活用できるようにさせることです。考え得る最悪のスクリーン スクレーパーを伴ったグリーン スクリーン アプリケーションでさえ、このような演算能力およびI/Oを低下させることはできません。また、ディスク アレイも到底及びません。何テラバイトものメイン メモリー、何十テラバイトものアドレス指定可能な不揮発性ストレージ、何ペタバイト~何十ペタバイトものフラッシュ ストレージを搭載した、システム バス内の帯域幅が1テラバイト/秒、そしてコンピュート コンプレックスへ繋がれるメモリーおよびI/O帯域幅がその2~3倍である、72コアの2ソケットシステムを想像してみてください。IBM i がHPCおよびAIへと進むべき時が来たのです。