POWER10のパフォーマンス
サーバーを購入し、それらを組み合わせてシステムを構築する多くの組織にとって、気になる最も重要なパフォーマンス メトリックは、それぞれのマシンごとの全体的なスループットです。しかし、多くのIBM i のショップにとっては、そして実にSystem zメインフレーム ショップにとっても、最も重要なメトリックはコアごとのパフォーマンスです。というのも、ほとんどのIBM i 顧客の場合、マシンのコア数はあまり多いわけではないからです。コアが1つだけというショップもあれば、2、3、または4つのショップもありますが、それより多いケースはほとんどありません。もっとも、非常に大型のPower SystemsがIBM i を稼働しているケースもあります。ただし、それは120,000件の重複しない顧客ベースのうちの、数千件ほどの顧客に過ぎません。
したがって、私たちが特に興味を持つことになるのは、今後のPower10プロセッサーのパフォーマンスが、単一のコアのレベルで、前の世代のPowerプロセッサーと比べてどの程度になるかということです。どのような精度であれ、これを割り出すのは難しいことですが、8月のHot ChipsカンファレンスでのプレゼンテーションでIBMは、Power 10ソケットのパフォーマンスがどのあたりになりそうか、ある程度推定するのに役立ちそうないくつかの手掛かりを示してくれました。そこから逆算することで、IBMがIBM i システムの相対的パフォーマンスの測定に使用しているCommercial Performance Workload(CPW)ベンチマークのスコアで、Power10のコアはどのあたりに位置付けられることになりそうか探ってみようと思います。
最近のいくつかの世代間でパフォーマンスがどの程度向上しているのかを見直してみましょう。Power7+からPower8への移行では(後者は2014年に発表)、ソケット レベルでの生の整数パフォーマンスは、2.2倍に向上し、TPC-Cおよびその他のテストによって測定される他の商用ワークロードでのパフォーマンスは約2.7倍に向上し、Javaワークロードでは2.5倍強に向上しています。これらの数値は、2013年のHot Chipsで発表されたものです。Power9チップ発表の前年である2016年、Power9ソケットのパフォーマンスのプレビューを行っていた時点では、IBMは、Power9のソケット当たりのパフォーマンスは、生の整数パフォーマンスで約1.8倍高くなり、商用アプリケーション向けではもう少し高くなるだろうと述べていました。以下のグラフは、Power9を基準とした、Power10のソケット当たりでのパフォーマンスについてIBMが予想したものです。
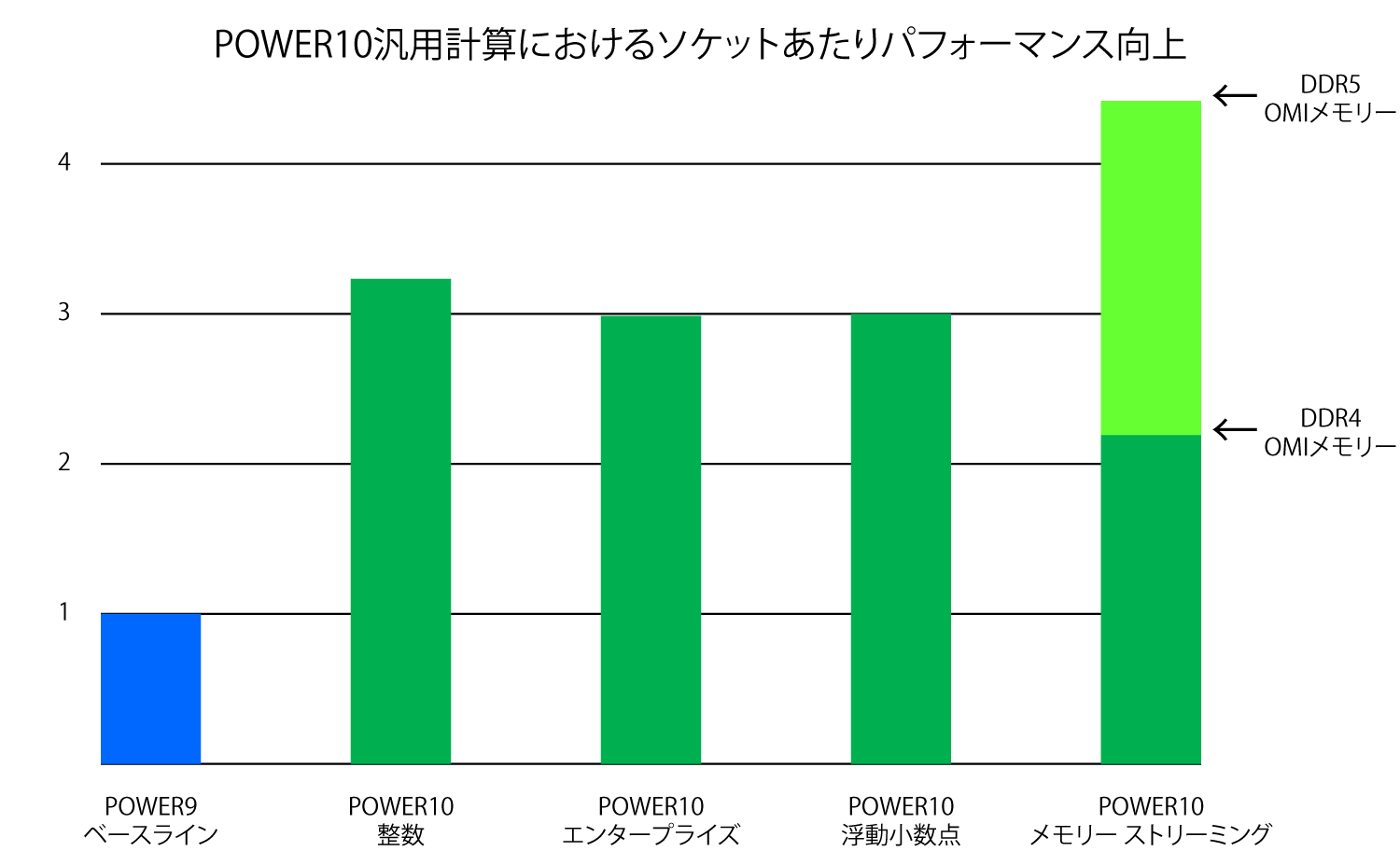
コア数が増加し(Power9の12からPower10の16へ。ただし、Samsung社のファウンドリーでそれらの製造のために採用される7ナノメートル プロセスでの実効的な生産性を向上させるために15コアのみがアクティベート)、また、初めからコアを完全に作り直したおかげで、Power10ソケットの生の整数パフォーマンスは3倍を超え、エンタープライズ ワークロード(先のプレゼンテーションでは商用ワークロードと呼ばれていました)では、ちょうど3倍に向上することになります。IBMは、過去数世代のPowerプロセッサーで4 GHzのデザイン スペックを使用してきましたが、Power10でも同じだと私は思っています。
これは今日のIBM i のショップにとって重要というわけではありませんが、Power10チップ ソケットのベクトルおよび行列演算パフォーマンスは、さらに大幅に向上することになります。これは、拡張された演算ユニットおよび混合精度のサポートのおかげであり、機械学習トレーニングおよび推論ワークロードにとっては重要なものです。機械学習の推論は、今後数年のうちに、IBM i で稼働するものを含めて、多くのアプリケーション内で重要になるでしょう。私の予言を覚えておいてください。そのため、今のところは特に関係なさそうだとしても、注目しておく価値はあります。次のグラフは、そのデータを示したものです。
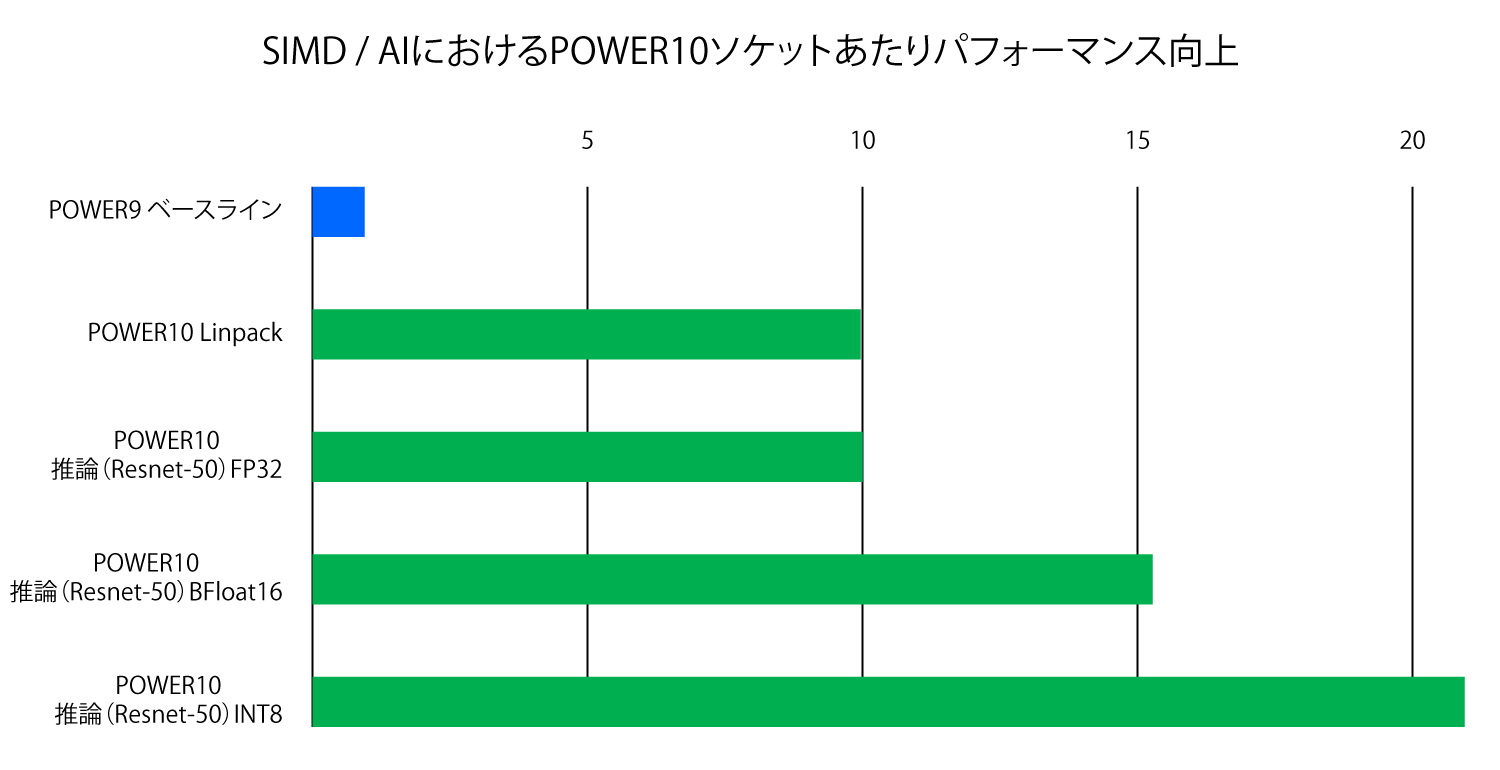
これが重要となる理由はこうです。推論は、ハイパースケーラーにとってそうであるように、必ずしも非常に重いワークロードとなるというわけではなく、おそらくは、オペレーティング システム、データベース、およびミドルウェアにおける自己監視および自己回復機能から、SoR(記録のためのシステム)においてアプリケーションのあらゆる場所に散りばめられているAIアルゴリズムまで、そしてSoE(エンゲージメントのためのシステム)の支配的ではないにしても主要な部分であるAIルーチンまで、ソフトウェア スタックのすべての面に埋め込まれることになりそうです。多くの場合、機械学習トレーニング ワークロードを実行するにはハイブリッドCPU-GPUシステムのような専用ハードウェアを必要としますが、機械学習の推論(これはモデルを構築するものではなく、ニューラル ネットワーク モデルをベースにしたアプリケーションです)は、CPU上でまったく問題なく動作します。ただし、これらのモデルがスループットを向上させるために使用する混合精度浮動小数点および整数演算をサポートしていることが条件です。Power10チップは、同じ4 GHzのクロック スピードで、Power9の10倍の生の倍精度(64ビット)浮動小数点演算性能を詰め込み(このこと自体、目を見張るものがあります)、ゲノム解析、信号処理、および機械学習の推論で使用される単精度(32ビット)浮動小数点で、パワーは10倍ということになります。しかし、GoogleによってそのTPU推論エンジン(ダイナミック レンジは32ビットFPですが、精度は少し低いため、演算ユニットで半分のスペースを占めるのみです)向けに作成されたBFloat16フォーマットをサポートすれば、推論処理は、Power10ではPower9に比べて15倍以上高速に実行し、さらに低精度の8ビット整数フォーマット(INT8)を使用すれば、推論性能はおよそ22倍に向上します。そうなると、多くの企業は、FPGA、GPU、またはカスタムASICをベースにした推論アクセラレーターを導入する必要がないということになります。このことは、この10年間のIBMのアクセラレーテッド コンピューティングというメッセージに矛盾することになりますが、推論ワークロードが極めて巨大であることから、これらのデバイスを必要としている組織は現在も数多くあります。ご存じの通り、ITの世界ではよくあることです。
ここから、2001年以降の、OS/400およびIBM i を稼働するPowerチップ ファミリーの歴史を見てみましょう。2001年には、デュアルコアPower4チップが初めて出荷され、ともに大幅に縮小していたプロプライエタリおよびUnixサーバー ビジネスの引き継ぎへとIBMを向かわせました(IBMが勝者で、他社、すなわちHewlett Packard社やSun Microsystems社が敗者だったのでしょうか。私はどちらとも言えると思います)。次の表をご覧ください。
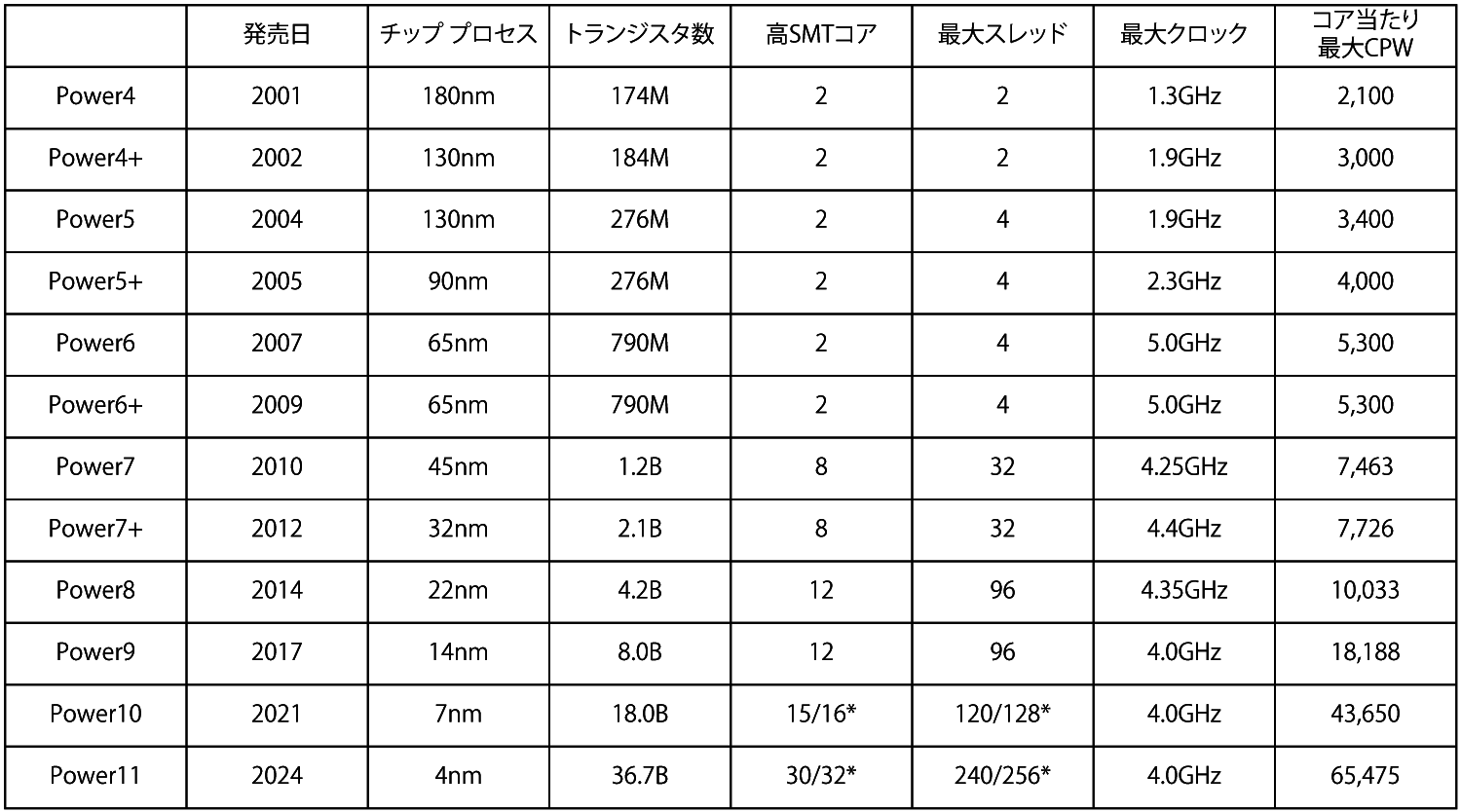
上の表は、発売時期、チップ プロセス技術、トランジスタ数、最大の同時マルチスレッド(これは1990年代のAS/400ラインで使用されたPowerPCチップの「Star」ファミリーに遡るものですが、Power4およびPower4+チップにはありませんでした)でのチップのコア数、コア当たりのSMTでのソケット当たりの利用可能な最大スレッド数、クロック スピード、そして最後にCPWテストでのコア当たりパフォーマンスの関係性を示したものです。これらは、各世代で利用可能なモノリシック チップの顕著な特徴です。IBMは、過去に何度もチップレットとマルチチップ モジュールの両方を用意したことがあったため、これはまったく新しいことというわけではありません。Power5およびPower5+にはデュアル チップ モジュールがあり、また、Power6+およびPower7+もそうでした。Power8にはハーフ チップレットがあり、12ではなく6コアのみで、これらのうちの2つが1つのソケットに入れられました。
以前の記事で述べたように、 Power10チップはデュアル チップ モジュール バリアントで提供されることになります。これは、間違いなく魅力的なものとなるでしょう。上の表のPower10のデータは、シングル チップ実装用であり、16コアですが、そのうちの15コアのみがアクティベートされます。IBMは、Samsungファブで製造される16のコアのうち少なくとも1コアは最初から不良となると正直に述べています。これは、7ナノメートル プロセスが新しいものであることと、Power10のようなファット チップの製造についてSamsungが習熟途上であることによるものです。IBMとSamsungがPower11で4ナノメートル プロセスへ移行するときには(IBMは5ナノメートル世代をスキップすると思われます)、クロック スピードをガバナーで調節することによって電力消費を抑制して、Power11チップレットのサイズを少し大きくし、さらにチップレットのコア数を2倍にすることができるだろうと思います。IBMはPower11 DCMを用意するでしょうし、QCM(クアッド コア モジュール)さえ用意することもあるかもしれません。QCMなら、ソケット当たりのパフォーマンスは大幅に向上します。Power10とPower11が共通のソケットを使用するとしても驚きではありませんが、おそらくPower11はDCMに制限されるでしょう。
ここまで述べてきたこと、そしてIBM提供の大まかなパフォーマンス データから推定すると、単一のPower10 コア のパワーは、おおよそ43,000 CPW前後となるのではないかと思われます。比較対象を探してみれば、これは、2002年の、8ウェイ16コアのPower4+システムとほぼ同じくらいのパフォーマンスと言えそうです。20年間で、コア当たり20倍のパフォーマンスの向上ということになり、これはなかなか立派なものです。また、これらのPower10コア(16コアすべてが起動し、使用できるとして)の シングル ソケット では、2010年および2012年の12ソケットのPower7またはPower7+システムと同じくらいのパフォーマンスということになるでしょう。ちなみに、これは、6ソケットのPower8マシン(IBMが作成したとして)、または3ソケットのPower9マシン(IBMが作成することはありませんが、Power E950にプロセッサーを3つだけ搭載すれば出来上がりです)ともほぼ同等ということになります。
Power9からPower10への移行の際に絞り出すことができたのと同じくらいのパフォーマンス向上は、Power11コアへの移行からは絞り出すことができないのではないかと思います。Power10のケースは、Power10コアが完全にリライトされたこともあり、コア当たりでパワーが平均して約2.4倍になったことによるものです。それでも、Power10からPower11への移行では、コア当たりで1.5倍くらいは絞り出すことができそうであり、そうなれば、コア当たりCPWは65,000くらいになるのではないかと思われます。これは、2012年の12コアの単一のPower7+プロセッサーとほぼ同等です。
IBMに願うとしたら、今後のPower10およびPower11プロセッサーのこのようなパフォーマンスを、手頃な価格でIBM i ワークロードに解放してもらえるとよいのだが、ということでしょうか。また、システムが行うことができる仕事を、他にもたくさん見つけてもらえるとよいと思います。そうすれば、顧客は、より少ないキャパシティーを購入するのではなく、より多くのキャパシティーを購入するようになるでしょう。どのみち、1つのコアの1/4を購入するということはできません。パフォーマンスがどれだけ向上したとしても、大切なのは、顧客にそれを使用してもらうことです。