IBM i 顧客サポートの事例紹介、ケース2 - CPUキューイングの待機時間に対処する -
車を運転しているときには、なるべく赤信号や渋滞は避けたいと思うものです。私たちは皆、動かずに待つということは大嫌いだからです。コンピューター システムのアクティブなジョブも、同じように待機に遭遇することがあることについては、程度の違いこそあれ、おそらく皆さんもお気付きだろうと思います。IBM i開発者チームは、様々なタイプの待機を類別しています。
この記事では、CPUキューイングの待機時間について取り上げます。CPUキューイングの待機時間について理にかなった方法で調査して問題に対処することにより、低パフォーマンスの問題の解決につなげるにはどのようにしたらよいか見て行きます。ここでは、素晴らしく有用なパフォーマンス レポート ツールを使用して、待機時間分析に役に立つアプローチを紹介しようと思います。
まず、CPUキューイングの待機時間をどのようなものとして捉えたらよいでしょうか。IBM i リリース6.1の時点で、ブラウザベースのNavigator for iシステム管理GUIツールの下に、IBM i Performance Data Investigator(PDI)という新たな組み込みGUIパフォーマンス レポート ツールが提供されました(詳細は、 https://developer.ibm.com/tutorials/ibm-i-performance-data-investigator/を参照してください)。PDIを使用すると、数多くの有用なパフォーマンス データの図表を表示することができ、CPU使用率、ディスクI/Oワークロードおよび応答時間、メモリー障害、および待機時間など、IBM i のパフォーマンス ヘルスの様々な側面を分析するのに役立てることができます。この記事では、CPUキューイングの待機時間のデータの見方について皆さんに理解してもらえることを目指します。
2021年、システム管理タスク向けのNavigator for iツールに、Log4j V1.xの脆弱性が見つかった件について触れておきます。IBMでは、Log4j V1.xを使用していないNavigator for iの新バージョンを提供しています。この新たなツールの使用法についての詳細は、 こちらのIBM Security Bulletin (脆弱性情報)を参照してください。
PDIの非常に有用な図表のグループの1つに、「待機」カテゴリーがあり、「CPU キューイング」はこのグループ内にあります。待機時間データはIBM i 5.4で導入されましたが、このリリースには、そのデータを表示するPDIツールはありません。この待機時間カテゴリーを調べるには、代わりに、関連のあるパフォーマンス データ ファイルを直接照会します。これを行うのはいくぶん複雑です。長年、IBM i のパフォーマンス分析に携わってきた経験からすると、IBM i 6.1以降は、待機時間データは、パフォーマンス問題を分析する際に非常に助けになっていると明言することができます。
まず、「待機」カテゴリーの下の、「待機の概要」と「汎用ジョブまたはタスク別の待機」という2つの図表を確認することが常に必要です(「ジョブまたはタスク別の待機」という図表もありますが、私の経験では「汎用」の図表の方が有用だと思います)。では、これら2つの図表の例を見てみましょう。以下は「待機の概要」の例です。
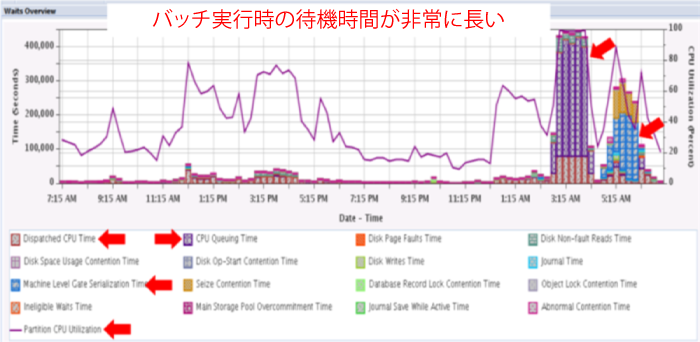
この24時間のタイムラインの「待機の概要」図表では、「区画の CPU 使用率」の折れ線グラフが、午前3時~午前4時に100%に達しています(グラフ右上の赤い矢印を参照)。これは、私がこの分析をお手伝いした顧客にとってクリティカルな夜間バッチ処理の時間帯でした。このバッチ実行の時間帯の5本の縦棒グラフではすべて、「ディスパッチされた CPU 時間」を表す比較的短い棒グラフのすぐ上に、分量が非常に多い「CPU キューイング時間」の棒グラフが積み上げられていることが見て取れます。図表の下半分の左側にある色凡例を見ると、これらの線および棒グラフ コンポーネントが何を表しているかを確認できます。1本1本の縦棒グラフは、それぞれパフォーマンス データのサンプリング間隔を表します。この例では、サンプリング間隔は15分に設定されていました。したがって、5本の縦棒グラフは1.25時間の時間帯を表します。
この、CPU使用率100%のクリティカルな時間帯の、それぞれの縦棒グラフで、「ディスパッチされた CPU 時間」の割合と、その上に積み上げられているすべての待機時間の合計を比較してみてください。すべての待機時間の割合が、「ディスパッチされた CPU 時間」の割合に比べて圧倒的に多い場合は、パフォーマンスが良くないことを示しています。これは、ジョブがアクティブに実行されている時間よりも、ずっと長い間、ジョブが待機状態に置かれているからです。このことは、上の5本の縦棒グラフにも当てはまります。車の喩えで言えば、一群の車(ジョブ)が、この1.25時間の時間帯の間は、動いている時間よりも赤信号で停まっている時間の方が長いと言うことができます。
パフォーマンス ヘルスとして良好レベルないしは許容できるレベルと私が判断する大体の目安は、それぞれの縦棒グラフで、「ディスパッチされた CPU 時間」の割合がすべての待機時間の合計以上になっているケースです。上の図表では、バッチ処理の時間帯以外の時間が該当しそうです。そこでは、それぞれの縦棒グラフで、すべての待機時間の合計部分がCPU時間の部分を超えないことが見て取れると思います(小さい縦棒グラフですが、「拡大」機能を使用すると見やすくなります)。
時間的に隣接していないで散在している何本かの縦棒グラフで、すべての待機時間の合計が圧倒的に多くなっている場合は、それほど心配する必要はないかもしれません。これも車の喩えで言えば、目的地まで青信号を通過できることの方が多く、赤信号で停まっている時間が少ないというのに似ています。非常に良好なパフォーマンスの例は、すべての縦棒グラフで、合計した待機時間が非常に少ないかまったくなく、「ディスパッチされた CPU 時間」のみが見えているケースです(この例については後述します)。
クリティカルなバッチの時間帯へ戻ると、「CPU キューイング時間」が唯一の圧倒的な待機コンポーネントとなっていることは明らかだと思われます。これは、それぞれの縦棒グラフの一番上に積み上げられている、他のすべての待機時間の合計が非常に小さいためです。
これはデータの「フォレスト」ビュー(データを森として見る見方)です。それぞれの縦棒グラフにおける、すべてのこうした時間が、サンプリング間隔ごとにすべてのアクティブなジョブから集められているためです。24時間の図表全体にわたって、すべての縦棒グラフで「ディスパッチされた CPU 時間」が圧倒的なコンポーネントであり、他のすべての待機時間がほとんど見られない場合は、その日が良好なパフォーマンス ケースだったと判断することができます。しかし、そうでない場合は、今度は「ツリー」ビュー(データを木として見る見方)へ掘り下げて見る必要があります。この例では「CPU キューイング時間」が圧倒的になっていますが、次は、まさにこの圧倒的な待機時間が1つまたは少数のジョブでのみ発生しているのか、ほとんどまたはすべてのジョブに分散しているのか、自問してみる必要があります。
後者である場合は、全体的なワークロードが、利用可能なCPUパワー全体を圧倒している単純なケースということになるかもしれません。とすれば、この状況に対処するには、単により多くのCPUコアをアクティベートさせるだけです。
前者の場合、つまり、圧倒的な待機時間が、1つのジョブ、または同様のジョブから成る特定のグループでのみ発生する場合は、ジョブを修正して、圧倒的な待機時間(このケースでは「CPU キューイング時間」)を減らす方法を見つけるチャンスということになります。この分析ステップを実行するには、「汎用ジョブまたはタスク別の待機」という図表を表示する必要があります(下図参照)。
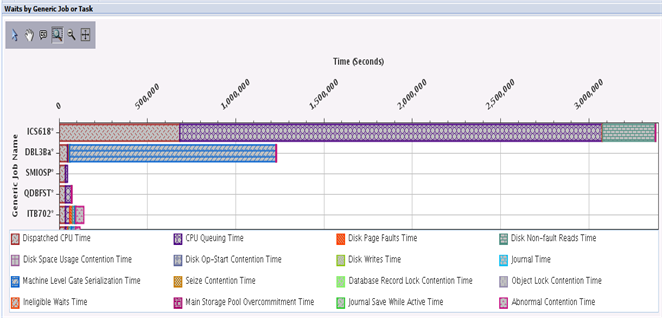
この図表の横棒グラフは、それぞれジョブ名の汎用グループを表します。つまり、それぞれの横棒グラフは、名前の最初の6文字が同じであるすべてのジョブのすべての時間を1つの項目として集積したものです。このことは、IBM i で実行されているジョブの名前の最初の6文字が同じである場合は、それらのジョブはおそらく同じプログラムを実行しているだろうということを前提としています。それらは、同じ24時間のタイムラインで、並行してまたは異なる時間帯で実行される場合もあります。
汎用ジョブ名の最後のアスタリスクは、完全ジョブ名が6文字より長いことを意味しています。名前の最後に「*」が付いていない場合は、完全ジョブ名が、表示されている通りの名前であることを意味します。そして、そのような横棒グラフが、1つまたは複数のジョブを表すこともあります。前述の「待機の概要」図表に表示されていたものとの関連性を確認するには、表示される汎用ジョブ名または特定のジョブ名を使用する必要があるため、この命名規則は重要です。
上の両方の図表を見てみると、ICS618*という名前の汎用ジョブ(すぐ上の図表の一番上の横棒グラフ)は、圧倒的な量のCPUキューイングの待機時間を集積した唯一のグループであることが明らかだと私は思います。顧客によれば、ICS618*ジョブが実行されたのは、1つ目の図表に見られたクリティカルなバッチ実行の時間帯のみだということでした。このことから、これらのジョブが、過大な量のCPUキューイング時間を発生させる、唯一ではないにせよ主な要因だということが浮き彫りになり、だからこそ、ここでの問題解決の中心的な検討対象となるわけです。さらに話を聞いたところ、顧客は300件の並行するICS618*ジョブを実行していて、それぞれが、組み込みSQLやOPNQRYFで同じRPGプログラムのグループを実行していたとのことでした。
では、問題の解決策を探ってみましょう。
CPUキューイングの待機時間が莫大で不必要な量であることと、顧客のサーバーに搭載されているPOWER8 CPUコアは10個ということを結び付けてみると、300件の並行するバッチ ジョブというのは、利用可能なすべてのCPUコアに対して圧倒的に多過ぎると判断するのが合理的です。また、顧客によれば、この並行ジョブの数は、特別な理由もなく決められたということです。そのような並行ジョブの最適数を判定するのは簡単ではないかもしれないと思われましたが、以前に何度かこのような状況に対応したことがあり、また、顧客のコア アプリケーション(IBM i でポピュラーなISVソリューション)にたまたま馴染みがあったことから、Power8、Power9、およびPower10コア1個当たり、「重量級ジョブ」は5件または6件、という大まかな目安を考えてみました。顧客には、300件ではなく60件のジョブを実行して、全体の実行時間および待機時間の結果を観察してみることを提案しました。誰もがホッとしたことに、バッチ処理の全体の実行時間は、元の1.25時間から約15分改善することができました。より重要なことに、「待機の概要」図表では、CPUキューイングの待機時間は、それぞれの縦棒グラフの一番上のほんの小さな点のように劇的に小さくなっていました。さらに並行ジョブを少し減らしたところ、CPUキューイングの待機時間はすべてなくなりました。
ここで目指している重要な便益は、バッチ実行時間の改善ではないということを確認しておきたいと思います。絶対数という言い方からすれば、ほんのささやかな改善だからです。このケースでより重要な便益は、圧倒的な量のCPUキューイング時間をなくすことです。この種の待機時間が圧倒的な量で発生しているときは、その時間帯に実行されているジョブが、ひどく悲惨なパフォーマンスの犠牲になるからです。こうした待機時間がなくなれば、すべてのジョブが、一貫した申し分のないパフォーマンスで実行されるようになります。これこそが、私たちの誰もが目指している便益です。
これまでの経験を踏まえると、多くのIBM i 顧客は(私自身も含めて)、全体のバッチ実行時間を最適化するために、利用可能なCPUパワーを基にして、どのように並行バッチ ジョブの最適数を決めたらよいかという問題に奮闘してきました。多くの顧客は、余裕を見て、多めの数にしているようですが、彼らのPDIレポートを見ると、結果的に、過大なCPUキューイングの待機時間が発生することが頻繁にあるようです。こうしたCPUキューイングの時間分析のおかげで、ようやく奮闘にケリがつくことになりました。いったん覚えてしまえば、この分析手法は単純明快だということにご同意いただけるのではないでしょうか。
また、こうした圧倒的な待機時間を分析するアプローチは、「待機」図表の凡例欄に表示されている他のタイプの待機時間にも応用できますが、他の待機時間に対応するための個々の方法は、それぞれ異なります。たとえば、実際の「ジャーナルの時間」を調べる場合は、IBM i Journal HA Performance製品を購入およびインストールして、関連のあるジャーナル オブジェクトの「Journal Cache」パラメーターをオンにしておく必要があります。実際の「Disk Page Fault Time」を調べる場合は、ディスク応答時間が遅かったり、メモリー ページ フォールト率が異常に高かったり(またはその両方)している状況であることから、ディスク ハードウェアのアップグレードを行ったり、異常に高いメモリー フォールト率の原因となっているジョブを特定して、それを減らすことを試みたりする必要があります。例を挙げればきりがありません。
良好な全体的なシステム パフォーマンスというのは、「待機の概要」図表では、いったいどのようなグラフになるのかと思われるかもしれません。以下に例を示します。
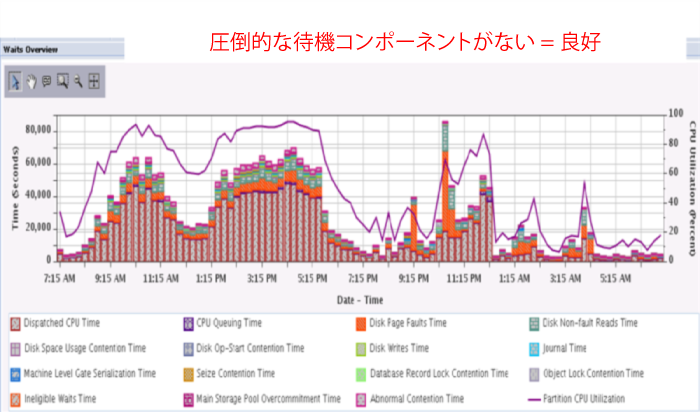
この24時間の図表のすべての縦棒グラフを1本ずつ見てみると、それぞれの縦棒の先端部に小さく表示されているすべての待機時間の合計に比べて、いつでも圧倒的に大きな部分を占めているコンポーネントは「ディスパッチされた CPU 時間」であることが分かると思います(多少、例外はありますが、気にする必要はありません)。そのようなケースでは、昼間の時間帯全体で全体的なCPU使用率は、一貫して高めですが、CPUキューイングの待機時間はほとんど見られません。
この最後の図表は、サーバー ハードウェアおよび一部のオペレーティング システムの観点からすると、全体的なシステム パフォーマンスとして申し分のないケースです。だからと言って、ITインフラストラクチャー環境に、協働している複数のサーバーが含まれている場合に、パフォーマンス問題が発生しないというわけではありません。そうした環境は、最新のクライアント/サーバーおよびWebベースのアプリケーション展開では実に典型的な環境と言えるでしょう。そのようなアプリケーションのユーザーから、業務運用時のパフォーマンスが良くないと苦情が出た場合でも、上の例のように、「待機の概要」図表に、全体的な待機時間がほとんど見られないのだとしたら、問題の原因は、サーバー ハードウェアにも、ほとんどのOS機能にもないということになります。全体的な待機時間がほとんどないことからもそれは明らかです。どこか他にパフォーマンス問題の原因を探す必要があります。以前、そのようなパフォーマンス問題の外的要因に関して、顧客の支援に携わったこともありますが、その問題については、また別の記事で紹介する予定です。
最後にここで触れておきたいことは、IBMは、多くの古いAS/400およびiSeriesモデルについては、「CPU使用率%」のガイドラインを公開していたことです。しかし、POWER5ベースのサーバーの時代以降、IBMが仮想プロセッサー、上限なしパーティショニング、共有プロセッサー プールおよびその他の仮想化テクノロジーを提供してからは、「CPU % Busy」のガイドラインは、メトリックとして有用なものではなくなっています。サーバーのCPUが一日中90~100%で利用されているのを頻繁に目にすることがあるかもしれませんが、全体的なCPUキューイング(および、ここでは取り上げませんでしたが「Machine Level Gate Serialization Time」)がほとんどまたはまったく見られないのである限りは、IBM i サーバーには、全体的なシステム パフォーマンスの低下をもたらしそうな、差し迫った心配の種はないということになります。ただし、サーバーのCPUパワー サイジングやアプリケーション ワークロード展開の最適化、またはその両方に関しては、長期的な懸念材料はまだあります。
この記事が、PDIツールの有用なこれら2つの「待機」図表についての認識および理解を深めるのに役立ち、今後、それらを活用していただけるようになるのだとしたら幸いです。
IBM i パフォーマンスの調査という獲物を追いかけるゲームは、始まったところです。