JDBCR4 を使って RPG から外部データベースにアクセスする
時代は変わりました。何年も前なら、企業全体で IBM i (当時 OS/400 と呼ばれていました) を動作させており、RPG プログラムで動作する必要があった唯一のデータベース・ソフトウェアは DB2 for i でした。もはやこれは当てはまりません。現在では、ほとんどの組織が Windows 上でアプリケーションを動作させており、Unix でアプリケーションを動作させている組織も多数存在します。このため、RPG プログラムが外部のデータベース・サーバーにアクセスしなければならないケースが多々発生しています。
困ったことに、データベース・パッケージの多くには IBM i のネイティブ・ドライバーが同梱されていません。同梱されていたとしても、追加料金を支払うことになるでしょう。この問題を解決する方法として、RPG プログラムから JDBC を使う方法があります。Java はクロスプラットフォーム・テクノロジーであるため、純粋な Java (「Type 4」JDBC ドライバーと呼ばれています) で作成されたデータベース・ドライバーは IBM i を含め、どのプラットフォームでも動作します。V5R1 以降、RPG には Java ルーチンを呼び出す機能が備わりました。つまり、こうしたクロスプラットフォーム Java データベース・ドライバーを 、RPG プログラムから使うことができるということです。
どうやって動かすのか?
RPG プログラムから JDBC メソッドを簡単に呼び出すという目的で、RPG IV の JDBC を表し JDBCR4 を呼び出す RPG サービス・プログラムを作成しました。図 1 にそのプロセスの概要を示しています。JDBCR4 が JDBC Driver Manager を呼び出し、それがメーカーの JDBC ドライバーを使ってデータベース・サーバーにアクセスします。
JDBC ドライバーは、JDBC Driver Manager に直接スナップされるスナップオン・モジュールと考えたいと思います。このためには、使いたい JDBC ドライバーの Java クラス名を指定します。Java は JDBC ドライバーのそのクラスパスを検索し、ドライバー・マネージャーに「スナップイン」されるよう、そのクラスパスをロードします。可能性として、一度に多数の JDBC ドライバーをロードできます。これは、接続して複数のリモート・サーバー間でデータを転送する場合に便利です。
ドライバーがロードされたら、接続したい JDBC ドライバーを識別する URL と、接続先のサーバーのネットワーク・アドレスを指定します。リモート・サーバーでセキュリティーに関する資格情報を確立するには、ユーザー名とパスワードを指定する必要があります。
JDBC ドライバーをインストールする
JDBC ドライバーをインストールするには、接続先となるデータベース・ソフトウェアの Type 4 ドライバーを見つける必要があります。4 つの最も一般的なデータベースである SQL Server、Oracle、MySQL、DB2 の接続を図示しますが、JDBCR4 は、これら 4 種類のドライバーしか使うことができないわけではない点を理解してください。Type 4 ドライバーならどれでも動作します (正しい Java クラス名と URL がわかっていることが前提ですが)。
JDBC ドライバーは、次のリンクにある 4 種類の一般的なデータベース・パッケージからダウンロードできます。
- Microsoft SQL Server (オープン・ソース jTDS ドライバー使用):jtds.sourceforge.net
- Oracle (シン・ドライバー):oracle.com/technetwork/indexes/downloads
- MySQL: (通称 "Connector/J"):mysql.com/products/connector
ドライバーをダウンロードしたら、次の手順に進みます。
- ドライバーを Windows PC に解凍します。
- ドライバーが入った JAR ファイルを探します。
- mysql-connector-java-X.X.X-bin.jar
- Oracle: ojdbcXX.jar
- SQL Server: jtds-X.X.X.jar
- DB2 for i: jt400.jar または jtopen.jar
- IFS に JAR ファイルを保存する場所を探します。私のショップでは、その目的で作成した /java/jdbc というディレクトリーに JDBC ドライバーを保存しています。図 2 はディレクトリーの作成時に使ったコマンドを示しています。
図 2: JDBC ドライバー用の IFS ディレクトリーを作成するコマンド

- JAR ファイルをアップロードします。私の場合は、図 3 のようにバイナリー・モードで FTP を使います。
図 3: FTP で JAR ファイルをアップロードする FTP コマンド
- JAR ファイルを CLASSPATH (以下の「Java CLASSPATH を設定する」を参照) に追加します。
これでインストールは完了です。
データベース・サーバーに接続する
データベース・サーバーに接続する際に、 JDBCR4 の 2 つのルーチンのうちJDBC_Connect の方が簡単です。これを呼び出すには、ロードするドライバーの Java クラス名、Java に接続方法を指示する URL、ユーザー ID、パスワードの 4 つのパラメーターを指定します。図 4 に JDBC_Connect を呼び出す場合の例を示しました。
図 4: 接続パラメーターを確立し JDBC_Connect を呼び出す

クラス名と URL は接続先となるデータベース・サーバーにより異なるため、例をそれぞれ示しました。
MySQL (B)
![]()
SQL Server (C)
![]()
Oracle (D)
![]()
DB2 (E)
![]()
JDBC_Connect の出力は Java「Connection」オブジェクトです。RPG コードをシンプルに保つため、JDBC_H コピーブックに Java Connection オブジェクトの RPG テンプレートを作成しました。これによって RPG コードによる JDBC_Connect の呼び出しが簡単になります。図 4 の A が示すように、LIKE(Connection) になるように RPG 変数を宣言する D 仕様を作成するだけです。
図 4 の (A)
![]()
Connection オブジェクトは、データベース・サーバーへの接続を特定します。この記事の後半で、'conn' 変数を SQL ステートメントを実行する JDBCR4 ルーチンに渡します。そうすることで、どのデータベース接続にステートメントを実行するか JDBC Driver Manager に伝えます。複数のデータベース・サーバーに接続する場合、この Connection オブジェクトでそれらの間の違いが識別されます。
JDBC_Connect 中にエラーが発生した場合は、'conn' が *NULL に設定されます。JDBC_Connect を呼び出した後、図 4 の F で示すように、接続が成功したかどうか常に確認する必要があります。
図 4 の (F)

JDBC_ConnProp (「connect with properties」の略称) は、データベース・サーバーに接続する次の方法です。図 5 の JDBC_ConnProp の例でおわかりのように、JDBC_Connect より多少複雑になっていますが、より多様性が増しています。そうした多様性から、私は常に自分のプログラムでは JDBC_ConnProp を使っています。
図 5: Connecting with Properties
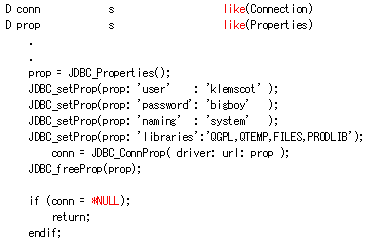
多様性の源は「プロパティー・リスト」です。このリストでは、接続の確立方法を指定する異なる変数を指定したり、使用する SQL セッションのさまざまな属性を設定したりできます。プロパティーのリストはデータベース・サーバーごとに異なるため、使っている JDBC ドライバーのマニュアルで、どのプロパティーが利用できるか確認する必要があります。
JDBC_ConnProp を使ってデータベース・サーバーに接続するには、まず接続するプロパティーのリストを宣言する必要があります。Properties は RPG コードの JDBC_H で宣言され、LIKE(Properties) で使うもう 1 つの Java オブジェクト・タイプです。Properties オブジェクトはひそかに RPG 配列と非常に似ています。 キーワードとその値のリストが含まれています。この例では、JDBC を使って DB2 for i データベースに接続しています。図 5 の A では、JDBC_Properties ルーチンを呼び出して新しい Properties オブジェクトを作成しました。
図 5 の (A)
![]()
B では、JDBC_SetProp を繰り返し呼び出して、プロパティーをプロパティー・リストに割り当てています。JDBC_ConnProp では、ユーザー ID とパスワードをプロパティー・リストに設定する必要があります。また命名規則を「system」(組み込み SQL で NAMING(*SYS) を指定する場合のように) に設定し、接続のライブラリー・リストを設定します。プロパティーは配列に似ているため、リストを作成するときは、単に値を配列に割り当てるだけである点を思い出してください。まだ、何もアクションは起こしていません。
図 5 の (B)

図 5の C で、データベース接続を行うために JDBC_ConnProp を呼び出しています。そうするには、Java クラス名、URL (図 4 の JDBC_Connect のケースと同様)、作成したばかりの Properties オブジェクトを指定する必要があります。これで、データベース接続が確立され、プロパティーが使われます。
図 5 の (C)
![]()
図 5 の D では、JDBC_FreeProp ルーチンを呼び出して、私がやったように、Properties オブジェクトが使っていたメモリーを解放しています。
図 5 の (D)
![]()
JDBC_ConnProp は、JDBC_Connect が戻したのと同じ型のオブジェクトである Java Connection オブジェクトを戻します、または接続が失敗したことを示す場合は *NULL を戻します。JDBC_Connect と JDBC_ConnProp は互いに代替手段となります。最終的に、結果はどれも同じになります。引き続き SQL ステートメントの実行に使うことができるデータベース・サーバーに接続されます。
SQL ステートメントを実行する
いったん接続したら (切断する前に)、データベースに対して SQL ステートメントを実行できます。ただし、SQL ステートメントは常に、データベース・サーバーの SQL 構文でコーディングする必要があることに注意してください。例えば、Microsoft の SQL Server で動作する SQL ステートメントを作成している場合、Microsoft の Transact-SQL の規則にしたがってコーディングすることになります。
JDBC の SQL ステートメントは、 SQL データベース・エンジンが認識する文字列でコーディングします。RPG プログラムにありがちな組み込み SQL 環境とは異なり、「静的」SQL ステートメントは存在しません。すべてのステートメントが動的です。SQL ステートメントを実行時にデータベース・エンジンに送り、文字列として解釈し、照会プランを考えだして、実行します。
JDBC は、「即時」と「準備済み」の両方の SQL ステートメントをサポートしています。即時ステートメントは SQL ステートメントを文字列として認識し、即座にそれを実行します。一方、準備済みステートメントは SQL ステートメントを文字列として認識しますが、すぐには実行しません。PreparedStatement Java オブジェクトを戻して、以降繰り返し実行できるようにし、その都度異なるパラメーター値を提供する可能性があります。即時ステートメントでは、準備済みステートメントよりコードは少なくて済みますが、ステートメントを複数回実行しようとしている場合は、準備済みステートメントの方が性能的に優れています。データベース・サーバーはステートメントを 1 回だけ解釈すればよいためです。
即時ステートメント
より簡単にコーディングできるため、即時ステートメントから説明します。即時ステートメントには、照会ステートメントと update ステートメントの 2 種類があります。行のセット (「結果セット」と呼ばれています) を応答する必要があるあらゆるSQL ステートメントに、照会ステートメントを使います。Select ステートメントは最も一般的に使われている照会ステートメントです。一方、update ステートメントは行のリストは戻しません。実際「update」という言葉は、誤解を与える表現です。たとえ何も更新しなくても、行のセットを返されないすべての SQL ステートメントが「update」ステートメントと考えられているからです。例えば、Create Table と Insert の両方は、 Update とともに update ステートメントと見なされています。
JDBCR4 の JDBC_ExecUpd ルーチンは、即時 update ステートメントを実行します (図 6)。
図 6: 即時 update ステートメント

このステートメントを実行する前に、JDBC_Connect または JDBC_ConnProp を呼び出してデータベースに接続し、'conn' という 接続オブジェクトを第 1 パラメーターとして JDBC_ExecUpd ルーチンに渡しました。第 2 パラメーターは、実行する SQL ステートメントを含む文字列です。文字列は図 6 で示すようにリテラルとして渡されるか、変数として構築され渡すことができます。
JDBC_ExecUpd ルーチンは、ステートメントの影響を受けた行の数を戻します。この例では、Create Table ステートメントはどの行にも影響を与えないため、ステートメントの実行に成功すると 0 が返されます。Insert または Update SQL ステートメントを実行すると、変更された行のカウントが返されます。ステートメントの実行でエラーが見つかると JDBC_ExecUpd は -1 を戻します。
JDBCR4 はまた、即時照会ステートメントを実行する JDBC_ExecQry というルーチンを提供しています。構文は JDBC_ExecUpd とほぼ同じですが、1 つ違いがあります。それは、SQL ステートメントから返された行と列のリストを表す ResultSet Java オブジェクトを戻すことです。組み込み SQL を良く知っているなら、結果セットはカーソルと同じであることに気付くと思います。ループ中の結果セットからレコード (SQL 用語で言う「行」) を取り出し、それらを処理します。その目的で、JDBCR4 は JDBC_nextRow というルーチンを提供しています。最初に JDBC_nextRow を呼び出すと、結果セットの最初の行に配置されます。以降の呼び出しは結果セットの次の行に配置されます。呼び出すたびに JDBC_nextRow は、次の行に無事移動した場合は *ON を、結果セットの終わりになると *OFF を戻します。
また JDBCR4 には、現在の行からフィールド (SQL 用語で言う「列」) を取得するルーチンがあります。JDBCR4 をシンプルに保つため、行のデータ型に関係なく、列の値を常に文字形式で戻すようにしました。必要ならば、RPG の %dec または %int BIF を使って、文字値を簡単に数値に変換できます。JDBCR4 は、列の値を取得する 2 つのルーチンを提供しています。JDBC_getCol はその番号で列の値を取得し、JDBC_getColByName はその名前で列を取得します。
図 7 に即時照会 SQL ステートメントの実行方法を示します。
図 7: 即時照会ステートメントと結果を読み取る

まず、Select ステートメントが入った文字列を JDBCR4 から JDBC_ExecQry ルーチンに渡します (A)。

次に、従業員マスター・ファイルの各行から従業員番号、従業員名、部門を取り出すごとに、ループの JDBC_nextRow ルーチンを実行します (B)。

行をすべて読み取ったら、ResultSet Java オブジェクトが使っていたメモリーを解放する必要があるため、JDBC_freeResult ルーチンを呼び出します (C)。
![]()
JDBC_getCol は、Select ステートメントに記載された列の順序に対応する番号を使って列を取得します。「Select Department, Employee_No, Employee_Name」とコーディングしたので、列番号 1 は Department、列番号 2 は Employee_No、列番号 3 は Employee_Name です。番号は常に SQL Select ステートメントの列を左から右に読み取って決定されます。
JDBC_getCol の代わりは JDBC_getColByName です。これにより、列の番号ではなく、列名で列を取得できます。図 8 は図 7 と同じ SQL ステートメントを示していますが、今回は、番号ではなく列名を使いました。
図 8: 名前で列を取得し NULL を処理する

図 8 の A で、第 3 オプション・パラメーターの RPG 標識変数を JDBC_getCol か JDBC_getColByName に渡すことで、列が NULL かどうかを確認する方法を図示しています。
図 8 の (A)
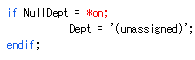
JDBCR4 は、列が NULL の場合はこの標識変数を *ON に、そうでない場合は *OFF に設定します。
準備済みステートメント
即時ステートメントのように、準備済みステートメントは照会ステートメントと update ステートメントに分けられます。ステートメントを準備するため、JDBC_PrepStmt を呼び出し、準備する SQL ステートメントが入った文字列を渡します。結果として 1 回または複数回実行できる PreparedStatement Java オブジェクトが生成されます。ステートメントを準備したら、再度準備しなくても複数回実行できます。
図 9 は、図 6 と 7 と同じ SQL Select ステートメントを示していますが、今回は準備済みステートメントとして示しました。
図 9: 準備済みステートメントと同じ照会

ステートメントを準備するために JDBC_PrepStmt (図 9 の A) を呼び出しました。
図 9 の (A)

照会ステートメントとして実行するために JDBC_ExecPrepQry (B) を呼び出しました。
図 9 の (B)
![]()
JDBC_ExecPrepQry の出力は ResultSet オブジェクトで、すでに説明した即時ステートメントの場合と同じです。すでに図示したように JDBC_nextRow と JDBC_getCol/JDBC_getColByName を呼び出してその結果セットを読み取るため、そのプロセスはここでは繰り返し説明しません。準備済みステートメントを作成したら、JDBC_FreePrepStmt を呼び出して、それが使っているメモリーを解放します (C)。
図 9 の (C)
![]()
準備済みステートメントを使う一番大きなメリットは、SQL エンジンが文字列を再度解釈しなくても、ステートメントを複数回実行できることです。例えば、前述の例で行ったように、すべての従業員を取得するのではなく、一度に 1 人の従業員を取得したいとします。図 10 では、2 つの従業員レコードを取得しています。まず、従業員番号 1000 と従業員番号 2000 を取得しています。SQL ステートメントへの各呼び出しのパラメーター値を変更するため、「パラメーター・マーカー」という機能を使いました。
図 10: JDBC 経由で 2 つのレコードを個別に読み取る

パラメーター・マーカーは、 SQL ステートメントにおける疑問符 (?) のようなものであり、スキーマ、表、または列名ではなく、列の値を表している場合があります。SQL ステートメントを宣言したとき (図 10 の A)、パラメーター・マーカー (疑問符) を where 節に配置しました。
図 10 の (A)

ステートメントを実行する前に、パラメーター・マーカーを番号 1000 に設定するため (B)、実行時に従業員 1000 を取得します。
図 10 の (B)
![]()
後で、2 回目の実行をする前にパラメーター・マーカーを 2000 に設定します (C)。
図 10 の (C)
![]()
ステートメントに挿入するデータのデータ型にしたがってパラメーター・マーカーを設定します。従業員番号は Employee_Master 表で整数列であるため、図 10 では、JDBC_setInt を使ってパラメーター・マーカーを設定しました。
図 11 は、Insert SQL ステートメントでパラメーター・マーカーを使っているところを示しています。
図 11: パラメーター・マーカーで多くの行を作成する

Insert は結果セットを戻さないため、JDBC 用語では「update」ステートメントと見なされています。パラメーター・マーカーは左から右へと採番されているため、Insert ステートメントを見ると (A)、employee_no、employee_name、department の 3 つの列があることがわかります。
図 11 の (A)

Values 節は、各列に対応するパラメーター・マーカー (疑問符) を一覧しているため、パラメーター・マーカー 1 は employee_no、パラメーター・マーカー 2 は employee_name、パラメーター・マーカー 3 は department になります。これらのパラメーター・マーカーは、ステートメントで左から右へ疑問符をカウントして得られます。
Employee_Master 表に 5 つのレコードを作成する必要があります (図 11 のB)。
図 11 の (B)
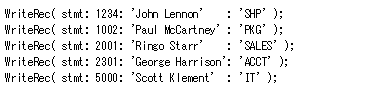
同じことを何度もコーディングしなくても済むように、WriteRec というサブプロシージャーを作成しました (C)。
図 11 の (C)

私のプロシージャーでは、3 つのパラメーター・マーカーを設定しています。従業員番号は整数であるため、第 1 パラメーターは JDBC_setInt を呼び出して設定されます。従業員名と部門は両方とも文字カラムであるため、それらの設定には JDBC_setString を使います。
列を NULL に設定するには、JDBC_setString、 JDBC_setInt、またパラメーター・マーカーを NULL または NULL 以外に設定する該当のルーチンで、追加のオプション・パラメーターを指定できます。列を NULL に設定する場合は *ON、それ以外の場合は *OFF に設定できる RPG 標識変数 (JDBC_getCol の変数と同様) です。
ストアード・プロシージャーを呼び出す
JDBCR4 には、ストアード・プロシージャーを呼び出すルーチンも入っています。ストアード・プロシージャーは複数の結果セットを戻し、完了時に更新カウント数も戻すことができます。そのため、「呼び出し可能ステートメント」と呼ばれる独自のステートメント・タイプを備えています。図 12 は、JDBCR4 からストアード・プロシージャーを呼び出しているところを示しています。
図 12: JDBCR4 を使ってストアード・プロシージャーを呼び出す

JDBC_prepCallStmt (A) は、すでに説明した準備済みステートメントとまったく同じように呼び出し可能ステートメントを準備します。
図 12 の (A)
![]()
JDBC_execCall (B) は呼び出し可能ステートメントを実行します。準備済みステートメントの場合同様、再度準備しなくても何度でも呼び出すことができます。
図 12 の (B)
![]()
JDBC_execCall は、少なくとも 1 つの結果セットがストアード・プロシージャーから返された場合に *ON、そうでない場合に *OFF に設定される RPG 標識を戻します。結果セットが利用できる場合、JDBC_getResultSet (C) を呼び出して、結果セットを取得できます。
図 12 の (C)
![]()
取得したら、JDBC_nextRow (D) を使います。
図 12 の (D)
![]()
また、すでに図示した他の結果セットの場合のように JDBC_getCol (E) を使います。
図 12 の (E)
![]()
次に、JDBC_getMoreResults (F) を呼び出して、別の結果セットがあるかどうか確認できます。
図 12 の (F)
![]()
JDBC_getMoreResults は処理していた結果セットを解放し、次に利用できる結果セットに配置して、プログラムに *ON を戻し、処理する結果セットがさらに存在することを示します (存在しない場合は *OFF を設定します)。以降、JDBC_getResultSet への呼び出しは、ストアード・プロシージャーから次の結果セットを戻します。通常は、ループで JDBC_getMoreResults を呼び出すため、ストアード・プロシージャーが戻したあらゆる結果セットを処理できます。
ストアード・プロシージャーで利用できるすべての結果セットを処理したら、JDBC_getUpdateCount (G) を呼び出して、ストアード・プロシージャーから更新カウント数 (ある場合) を取得できます。更新カウント数は、最後に取得する必要があります。
図 12 の (G)
![]()
データベースから切断する
JDBC_Connect または JDBC_ConnProp を呼び出すと、データベース・サーバーへのネットワーク接続が確立します。データベース・サーバーから切断する場合は、次のようにプログラム終了前に JDBC_Close を呼び出します。
![]()
閉じるのを忘れた場合は、プログラムが終了しても接続は自動的に閉じません ので、忘れないでください。予期しない理由でプログラムを終了前に閉じることができない場合、ジョブが終了すると接続が終了します。
コミットメント制御
デフォルトでは、ほとんどのデータベース・エンジンでは JDBC 接続は「自動コミット」モードになります。このモードは、各ステートメントが実行された後に、暗黙的にコミットされることを意味しています。これを変更するには、サーバーに接続した後に JDBC_AutoCommit(conn: *OFF) を呼び出します。その後、JDBC_commit を呼び出してトランザクションをコミットするか、JDBC_rollBack を呼び出してトランザクションをロールバックできます。
JDBCR4 を自分で試してみたい場合、www.scottklement.com/jdbc からコピーをダウンロードできます。幸運を祈ります。
Java CLASSPATH を設定する
JDBC ドライバーは、データベース・ソフトウェアのメーカーにより提供されたプリコンパイル済み Java クラス・ファイルで構成されています。これらは Java Archive (JAR) ファイルで配信されます。
Java クラス・ファイルは、RPG で *PGM オブジェクトか *SRVPGM オブジェクトを使うときとほとんど同じように使います。IBM i では、ストリーム・ファイル (*STMF) オブジェクトとして実装されたクラス・ファイルは IFS に保存されます。クラス・ファイルは JAR ファイルまたはディレクトリー内に常駐できます。クラス・ファイルが JAR ファイル内にある場合、Java の CLASSPATH で明示的に JAR ファイルを一覧し、検索する必要があります。
CLASSPATH は、クラス・ファイルを検索する際に Java が検索する IFS ディレクトリーまたは JAR ファイルの一覧を Java に提供する環境変数です。次の点を理解しておくことが大切です。
- 変数名 CLASSPATH はすべて大文字にします。
- ディレクトリーまたは JAR ファイル名はコロンで区切ります。
- 空白がパス名の一部として必要でない限り、CLASSPATH に空白を挿入しません。
- CLASSPATH に構文エラーがある場合は、Java はエラーを生成しません。検索している一部のクラスを見つけることができなくなるだけです。
- Java Virtual Machine (JVM) を最初に起動したとき、Java は CLASSPATH をジョブごとに 1 回だけ読み取ります。これは、通常ジョブ内で Java を最初に使った場合に発生するため、CLASSPATH を変更する場合は、サインオフして、再度サインオンし新しいジョブを開始します。
- CLASSPATH はジョブごとに 1 回だけ設定されるため、ジョブを通して使うと考えられるすべての JAR ファイルとディレクトリーを含めるようにします。私のショップでは、JDBC ドライバーとは別の他の JAR ファイルを使うため、CLASSPATH ではやるべきことがたくさんあります。
- プログラムにライブラリー・リストを設定しないように、プログラムには CLASSPATH を設定しません。システムまたはジョブの構成で設定します。
次の例では、jTDS (SQL Server) JDBC ドライバーだけでシンプルに CLASSPATH を設定しています。
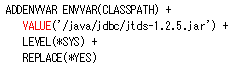
次の高度な例では、複数の JDBC ドライバーを設定しているだけでなく、jFreeChart と POI を設定しています。この例では、ジョブですべて必要だと思ったので、これらすべてを組み込みました。

これらの例で LEVEL(*SYS) を使ったため、CLASSPATH はシステム共通のデフォルトとして設定されます。この値は保持され (IPL 全体でも)、すべての新しいサインオンで、この値はそれらの CLASSPATH として設定されます。
同じコマンドを実行し、LEVEL(*JOB) を指定することで、ジョブ単位でこの設定をオーバーライドできます。この場合、設定は ADDENVVAR コマンドを実行するジョブにのみ影響を与え、LEVEL(*SYS) 設定に優先します。
私のショップでは、すべての実動ジョブの CLASSPATH を LEVEL(*SYS) で設定します。テスト環境で異なるバージョンの POI をテストしている場合、ログオンして、LEVEL(*JOB) を使ってテスト・バージョンを設定するだけです。